Swan Private Insight Update #29
This report was originally sent to Swan Private clients on November 10th, 2023. Swan Private guides corporations and high net worth individuals globally toward building generational wealth with Bitcoin.
This report was originally sent to Swan Private clients on November 10th, 2023. Swan Private guides corporations and high net worth individuals globally toward building generational wealth with Bitcoin.
If you’ve been learning about Bitcoin, you’ve probably heard a lot about hashes. So you might just be thinking:
“I don’t know what a hash is, and at this point, I’m afraid to ask. "
Fear no more.
Bitcoin leans heavily on a process called hashing to achieve many of its unique properties. Mining Bitcoin blocks with proof-of-work relies on hashing. Chaining together blocks to create the blockchain relies on hashes.
And while those aren’t even all the ways Bitcoin uses hashes, they are two of the most special applications. (Bitcoin also uses hashes to identify transactions, create addresses from public keys, and group all the transactions together in a single block.)
Without the unique things only hashes do, it would not be possible to create Bitcoin. But what actually is hashing?
This article aims to explain what hashes do that Bitcoin then uses to build a decentralized, consensus database consisting of blocks that are “chained” together. It aims to do it using simple terms and straightforward examples.
If you’ve been struggling to understand how Bitcoin actually accomplishes some of the exceptional things it does, you’ll hopefully have a couple of “aha!” moments.
Unfortunately, we can’t jump straight to those “aha” moments just yet. We’ll need to establish a couple of foundational ideas first. The first thing we need to understand is what a hash is, and in particular, what a few of the special properties of secure hashes are. Once we’ve done that, we can see how hashes can be cleverly used to do a few brilliant things that they’re used for in Bitcoin.
Disclaimer: This is neither a formal nor a complete explanation of hashing and isn’t intended to replace what you would learn by taking a formal class on cryptography. It really only focuses on the absolute minimum amount of content necessary to demonstrate what goes on in Bitcoin rather than how hashes get used in the world at large outside of Bitcoin.
What Is a Hash?
Let’s start with a really simple explanation of a hash.
A hash is a reasonably short number you get when you put a digital file into something called a hashing algorithm.
I hope the word algorithm doesn’t turn you off already. An algorithm is just a set of instructions for doing mathematical operations in a particular order on something you put into it. For example, “Multiply by 2 and then add 4” is an algorithm. So, if we’re cool with that word, I’ll get back to what a hash is.
Again, a hash is a reasonably short number you get when you put a digital file into a hashing algorithm. Whenever you put the same file into the hashing algorithm, the number it puts out is the same. In other words, the same input always leads to the same output. So, if I run the algorithm on a file and you run it on an exact copy of the same file, we’ll both get the same result.
This can be really useful if we each have a big file, and we want to see if the file we both have is the same or not. Instead of sending that huge file to each other and comparing each bit of it, we simply each run the hashing algorithm on the file we already have, and then we compare just the short results. If the two results are different, we know we didn’t both use the same file.
However, if we do both get the same result, then it means we might have the same file. But if the size of the hash result is itself too small a number, like a number between 0 and 1000, then any two different files could have a one-in-a-thousand chance of putting out the same result. If we want to use hashes for comparing files (which we very much, in fact do want to do), we need something more reliable — something whose results are more secure. And for that, we’ll need to leap straight into what makes something a secure hashing algorithm.
As we just explained, hashes can be used to compare two files to see if they are the same file or not. But while each hash of a file is a reasonably short number, to be a reliable source of comparison, the number of possible results still has to be large enough that we won’t ever mistake one file for another.
We need the possible range of numbers a hash can result in to be very big. After all, there are so many things we digitize — every photo on every smartphone, every email and text message, every song on Spotify, every video on YouTube, every Kindle book on Amazon, every jpeg on the Internet, and so on. We create tens of billions of new files every day, trillions of them every year, maybe even quadrillions. Maybe even more.
So, the first relevant feature for us of a secure hash is that it is a relatively short number that covers a tremendously large number of possibilities. In the case of Bitcoin, Satoshi chose to use Secure-Hashing-Algorithm-256 (SHA256). The “256” in its name indicates the output is always a 256-bit number. That means the result is a binary number (a bunch of zeroes and ones) that is 256 characters long. In decimal notation — the way we normally write down numbers — that’s a range of numbers between:
Now, at first glance, you may think that’s not a “reasonably short number” at all. Let’s not mistake big for long, though. It is a big number. It’s apparently as big a number as there are atoms in the visible universe. But it’s only seventy-eight digits long. Since we’re using these results to compare files that are millions, billions, or trillions of digits in length, the length of these hashes, being under a hundred characters, is relatively quite short. And yet, in a number this short, we can have a range of possible outcomes as vast as all the atoms in the universe!
The first requirement of a secure hash is that it covers a very wide range of possible outcomes while still being relatively short. And, as we’ve seen, SHA256 does that. The next two important requirements are closely related to and complement this first one.
Another crucial feature that makes a hash secure is that the result, or even any part of it, is completely unpredictable prior to running the algorithm on a file. There are several things worth pointing out about this feature.
One is that by looking at the hash of any single file, you can find out nothing at all about the original file itself. If you only have a hash of a file, all you have is a random-looking 256-bit number. You do not know how big the input file is, what kind of file it is, or anything about it or any part of it.
And conversely, until you run the algorithm on a file, you have no way of knowing what any part of the output will be, even if you’ve run the algorithm on very similar files before.
The result reveals nothing about the original file, and nothing about the original file gives you any clues about what the hash result will be.
A further implication of this feature is that if you have the hashes of two different files, no matter how similar these original files are to each other, the hashes look no more similar to each other than if the two original files had nothing in common at all.
The results must appear random.
For example, this means that if you use even two very similar inputs, like the text of Shakespeare’s “Romeo and Juliet” as the first input and the same text but with just one letter changed as the second input, the two results you get will not be any more similar than if you used a picture of a frog as the second input. This feature is sometimes called “hiding” in that the result of the hash of an input doesn’t reveal anything about that file other than what its hash is.
A hash basically just serves as a short and unique “fingerprint” of the original file.
Finally, and somewhat obviously, it is, of course, very important that we don’t end up with two different inputs producing the same result. A secure hash algorithm needs to be carefully created so that a “collision” of results (i.e., the same result) between two inputs is profoundly unlikely to occur.
There are other features of secure hashing algorithms, but we won’t explore them here. It is perhaps worth mentioning that hash functions cannot be reversed. There’s no way to take the short result and construct what the original input was. It’s also worth a brief mention that hashes need to be relatively fast to compute. If it took hours to generate a hash, we might often prefer to work with the original input file itself instead of its hash.
Another Disclaimer: If we had more space, we would, at this stage, go through dozens of basic examples of using hashes to become more familiar with them. But given the aim of keeping this as short as possible, we’ll dive right into how they end up getting used in Bitcoin.
So, we have this tool called a Secure Hash Algorithm. It takes any file as an input and then outputs for each file a random-looking number that is unique for that input. But that output isn’t actually random. If you put the exact same input in again, you’ll get the same result again. Thus, the hash serves as a unique “fingerprint” of the file that was the input.
We can put any digital file into a hash function. In fact, a hash result is itself a digital file. What if we tried to be clever and put into the hashing function something that itself contained the output of a hash?
Let’s look at an example.
Say you took the hash of the first photo on your phone’s photo library. For this example, let’s assume that photos are somewhere around 6 megabytes each, so each photo is hundreds of thousands of times bigger than the hash of the photo. (6 Megabytes is actually 48 million bits of information, and 48 million divided by 256 is 187,500 times as big). The hash is a unique and small fingerprint of photo number 1 in your photo library.
Next, we take that first short output and put it in front of the data that makes up the second photo in your photo library. We’ve temporarily created a new file that is only 256 bits longer than that second photo. It consists of the fingerprint of the first photo and the whole second photo. Now, we run the hash function on this new file. What would we get this time?
Well, we would still get a result that is only 256 bits long because that’s what the hash function always produces. But it is not the hash of the second photo. Instead, that result is now the unique fingerprint of something very special — it’s the fingerprint of the combination of, first, the fingerprint of the first photo and, secondly, the actual second photo. Why is this special (and what’s it got to do with Bitcoin)? Bear with me for just six more paragraphs, and we’ll see.
Imagine we keep this process going through the whole photo library on your phone, which, for our example, we will assume is 1,000 photos, so about 6 Gigabytes in size.
We continue taking the 256-bit result at each step, stick it in front of the next photo in the library, and run the hashing algorithm to get a new 256-bit number. We take a 256 result from the prior step each time, stick it in front of the next image in our library, and then run the algorithm to get a new 256-bit number. We keep all these short results in an ordered list.
Let’s look at what we’ve done. We have quickly (remember, hashes are quick to compute) and compactly created a database of 1,000 short 256-bit numbers. The size of the database is 256,000 bits in total (256 bits times one thousand) — a mere 32 KBs.
That’s still 187,500 times smaller than the photo library. But it’s not a hash of each photo. It’s a chain of hashes that starts with a hash of a single photo. Yet, each subsequent link in the chain is arrived at by hashing the fingerprint of the previous link with the next photo. Wherever we are in the chain, the result we have can only be arrived at if we use all the original photos in order to get there. When we arrive at the final photo, the 1000th photo, we take the 999th result and hash it together with the 1000th photo. Now, why might we do this?
Well, imagine we are maintaining a backup of our photo album in the cloud because we don’t want to lose our precious photos. In creating this progressive chain of hashes with photos, we are able to use this very small amount of data to see exactly how much of the photo gallery is perfectly copied into the cloud — and we can do it with blazing speed and accuracy. Let’s see how.
By running this same chaining process on the cloud backup of the photo library, we create a very easy tool for comparing not just whether the backup is complete but just how complete it is. We don’t have to compare the two libraries by starting at the beginning and going through the whole thing photo by photo. We don’t have to compare 1,000 individual photos or 1,000 individual hashes of photos.
Instead, we can start at the very end of both of the chains and compare the final hashes in both to see if they are the same. If both final 256-bit entries on our phone and the cloud backup are the same, it must mean that the entire photo libraries in both places are exactly the same! In doing that, we only compare two short 256-bit numbers and can determine that the two collections of files are exactly the same! That’s 187 million times faster than looking at the photos themselves!
More importantly, though, what if the final entries didn’t match?
In fact, every time you take a new photo or a bunch of them, this process runs, and now the final result on the backup does not match the final result on your phone. However, with the database we’ve created, we can very quickly find out where the backup left off. All the backup service needs to do is start at the end of the list you provide from your phone and work its way back until it gets a matching result. So whenever there isn’t a match, the backup service simply goes backward one result at a time through the list of hash outputs to see if it gets a match with the cloud backup. As soon as it finds a match, it knows that’s the point it is in sync with and only needs to copy everything from that point on. The backup service doesn’t need to confirm the accuracy of anything that came earlier!
For example, If the cloud backup’s final hash result matches with the 997th output in our phone’s list of hashes, the backup would know the following: It is a perfect match for all the first 997 photos in the photo library on the phone. It would know this without having to look at any one of those photos or any of the previous 996 hash results! And then it would know to copy only the final three photos, just 18 megabytes, instead of all 6 gigabytes.
In the above example, we used photos because we’re all familiar with them. We showed how we could use hashes to chain together hashes of photos with actual photos in order, one at a time. This allowed us to create and maintain a perfect backup without having to go through the whole database each time a new photo was added. The efficiency was incredible and ensured 100% complete accuracy in each photo in the library and even in the order of the library itself.
We may be less familiar with what Bitcoin blocks are than what photos are. However, hashes don’t care what the input is, so what works with the photo library example also works for what Bitcoin does with blocks of transactions.
Bitcoin doesn’t maintain just one single perfect backup of its database of blocks, though — it maintains as many backups as there are people who run Bitcoin nodes. Tens of thousands of people all over the world are able to copy and keep perfect, up-to-date copies of its database that is hundreds of gigabytes in size with minimal computational effort and minimal data transmission.
How?
By relying on chaining together these tiny hash results. As long as the hash of the last block they have matches that of the network, they can know with perfect certainty that all the data in all the blocks, from the genesis block until the latest block, is 100% precisely identical to that of everyone else’s.
This is because every Bitcoin node acts similarly to the backup service in the example above. It starts with the hash of the genesis block (which was represented by photo #1 in the above example) and hashes it together with the data from the incoming block. And this keeps going on, one block at a time, every time a new block is added. Whenever a node rejoins the network, it finds the last matching hash and downloads new blocks only from that point on to get in perfect synchronization.
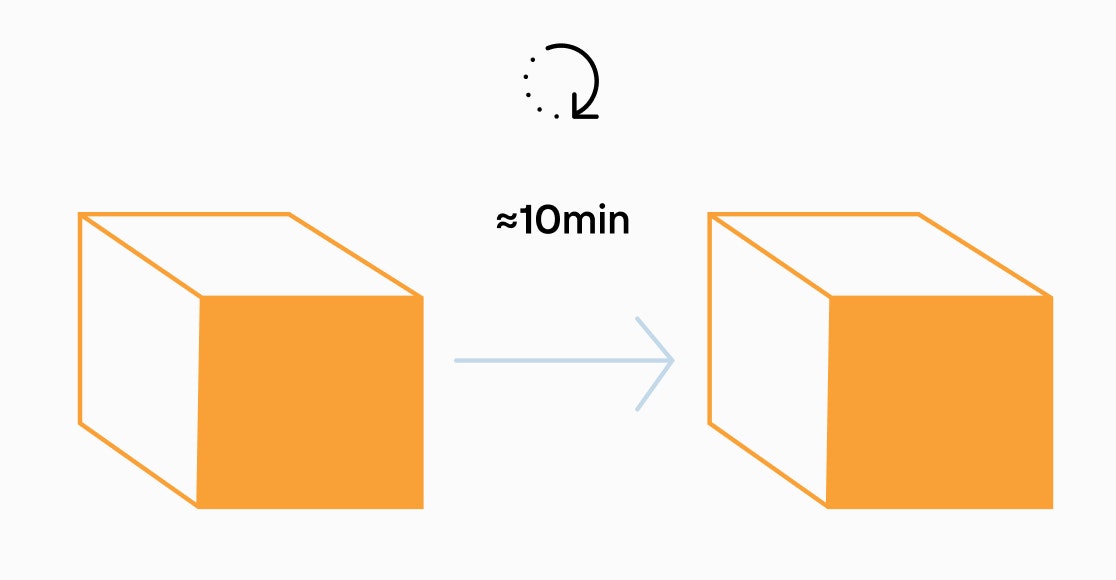
In the case of your phone’s photo library, you are allowed to add a photo whenever you want. But in the case of Bitcoin, we have a very different and unique situation. First, we want anyone to be allowed to participate in the process of adding a block — this is the nature of a decentralized and permissionless system. But we never said this would be easy. After all, Bitcoin only wants one new block added every ten minutes on average. Otherwise, the blockchain would grow too big, and we wouldn’t be able to keep backups of it on affordable and common hardware. Also, since Bitcoin pays a reward in Bitcoins to whoever adds a block, lots of people want to get that reward.
What’s a fair way of deciding who gets that reward?
How do we do all these things at once?
Satoshi wanted for anyone to be able to participate in the process of adding a new block, but that this would happen only once every ten minutes and that everyone would agree that one proposed new block in particular was going to be the next block instead of some other proposed block. He wanted this all to be done without a central authority declaring which block is next.
Let’s try to imagine how challenging this is with our phone photo library example again.
Imagine we were trying to maintain a photo library not linked to any one phone in particular but one where any phone in the world can upload a photo. There are a few catches we add-in. Lots of people are going to keep copies of the whole collection, so we need to keep it small enough for them to do so. We’re also only going to allow 10 photos in each update, and we’re also only going to add one such update of 10 photos once every ten minutes.
How do we decide which photos to include?
What makes one person’s proposed 10-photo-contribution valid and another’s invalid?
We’re also not allowed to ask people to register and then randomly choose one of them every ten minutes because we aren’t allowed to identify individuals in the system. And even if we knew everyone’s identity so we could try to choose one at random, what if that someone was chosen but wasn’t around to propose their addition?
What would we do then?
And who would do the choosing — some central or single authority?
This is a hopeless and unsolvable problem in the case of a photo gallery. Luckily, it’s not a useful problem to solve anyway. But in the case of Bitcoin, it is necessary we solve these challenges.
We need some method of choosing a valid next addition to the database (i.e., the addition of the next block) that still complies with the desired goals of one block every ten minutes, only valid transactions (no double spending, no spending non-existent coins), being under a maximum size limit, and picking up exactly where the last block left off.
We also need everyone to agree on what the valid next block is and for all of them to move on to the next block once one has been added. We also need anyone in the world to be able to participate in this process and everyone to agree on the outcome.
If this sounds like an impossible task to you, don’t beat yourself up about it. It was thought to be impossible until Satoshi showed how to do it with hash functions in the Bitcoin whitepaper.
Let’s recall that a hash is a fingerprint of a digital file. Its result is a 256-bit number. That means it can be greater than some particular number, less than that number, or equal to it.
And let’s recall that when you first put a file into a hash function, you have no idea what the result will be. It’s got a 50/50 chance of being greater than half that huge 78 digit-long number in the earlier section of this article and a 50/50 chance of being smaller. It’s also got a one in a trillion chance of being less than one trillionth of that number. Now, one trillionth of that number is still a very big number:
No matter what you put into the hash function, you’ve got only a one in a trillion chance of getting a result that (when expressed in decimal value) will be less than this number.
So what if we gave the following requirements for a proposed next block to be valid?
First, it had to have in its input the hash of the prior block (just like we did in how we constructed our photo library hash-chain). This would ensure that it was built on a precise and flawless copy of where the database last got updated. This is easy: just use the number you have.
Next, it would have to contain only valid transactions. This also is easy: don’t try including any invalid transactions.
Third, let’s make it so the hash of this data has to be less than that big number above. This is not so easy — you have a one-in-a-trillion chance of getting an outcome that meets this requirement.
If someone was proposing a new block, it would be easy to meet the first two requirements. But to satisfy the third requirement, they would have to create roughly one trillion different blocks before they found one whose hash was less than that target number.
While running a hash is quick, it’s not instantaneous, so it requires time and it also requires some computing energy. Running it a trillion times could take a long time and use up a lot of energy.
Therefore, for someone to create a block that everyone else would agree is valid, they would have to do a lot of work (and get lucky enough to find a solution before anyone else does). However, to prove they found a valid solution, they would only have to share the single valid result (a single block) with the rest of the network — not all the trillions of failed attempts they made. And all the network participants have to do to check if it is valid is to hash the single proposed block and see that its result is lower than the required target (and that it also met the first two easy conditions).
This is exactly how Bitcoin allows anyone in the world to participate in finding new blocks. By requiring that the hash of a block be a value lower than a particular target (as opposed to the number above) and by adjusting that target periodically so that the expected time between blocks remains an average of ten minutes, Bitcoin succeeds at meeting all the seemingly impossible requirements from up above.
1. It takes roughly ten minutes to produce a block everyone agrees will be valid;
2. Anyone in the world can participate in the process — anonymously and without signing up (both in trying to create blocks and in verifying their accuracy);
3. Nobody is in charge of deciding whose proposal is valid or not — the system itself sets the difficulty based on what is happening in the real world.
And so, we have a completely decentralized system where everyone can maintain and agree on the same database. Everyone’s copy is exactly the same. And we did it all by leaning on these interesting properties of hash functions.
I hope this article helped you better understand what hashes are and how Bitcoin uses them to create a database (its blockchain) that’s easily and perfectly replicated and kept up to date by tens of thousands of people all over the world without there ever being any discrepancy and with nobody in charge.
There’s a lot here to mentally process, so if you don’t feel like you’ve got it all yet, don’t worry. Let it sit with you for a bit. There’s also a lot more to hashes and a lot more to Bitcoin, so this is only an entry into understanding how they work together.
You may have lots of questions popping up in your head. One particular question I haven’t answered here is:
“What if two people find two different valid solutions to a block?
How do we decide which one we’ll keep?”
That’s a great question, but I had to stop somewhere. (The answer to that question is in the Bitcoin whitepaper in lots of other writings about Bitcoin, and Bitcoiners are very happy to answer it on social media, too.)
Knowing hashes exist, though, with their special properties and seeing how those properties are used can often spark one’s imagination and ideas around what is possible. And, from time to time, someone like Satoshi comes around and puts together these properties to create incredible inventions like Bitcoin.
Hold your IRA with the most trusted name in Bitcoin.
Tomer Strolight is Editor-in-Chief at Swan Bitcoin. He completed bachelors and masters degrees at Toronto’s Schulich School of Business. Tomer spent 25 years operating businesses in digital media and private equity before turning his attention full time to Bitcoin. Tomer wrote the book “Why Bitcoin?” a collection of 27 short articles each explaining a different facet of this revolutionary new monetary system. Tomer also wrote and narrated the short film “Bitcoin Is Generational Wealth”. He has appeared on many Bitcoin podcasts including What Bitcoin Did, The Stephan Livera Podcast, Bitcoin Rapid Fire, Twice Bitten, the Bitcoin Matrix and many more.
News
More NewsThoughts on Bitcoin from the Swan team and friends.
Bitcoin estate planning is the most under-addressed risk in HNW portfolios. Why holders and their CPAs, attorneys, and trustees keep missing it, and how to close the gap.
Learn how Bitcoin wealth management works, from custody and security to inheritance planning and liquidity. Discover how families and businesses use Bitcoin to build and protect long-term wealth.
Bitcoin vs. gold as a store of value in 2026: how they compare on scarcity, portability, and ownership & which better protects your wealth long term.